
 Peking University
Peking UniversityI am Qingyu Shi, a third-year PhD candidate at Peking University (PKU) under the supervision of Professor Yunhai Tong. Before that, I received my Bachelor's degree at Beijing Institute of Technology (BIT) in July 2023.
My research interests lie in the multimodal generation, with a particular focus on diffusion models and unified models.
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
Peking UniversitySchool of Intelligence Science and Technology
Ph.D. StudentSep. 2023 - present -
 Beijing Institute of TechnologyB.S. in School of Mathematics and StatisticsSep. 2019 - Jul. 2023
Beijing Institute of TechnologyB.S. in School of Mathematics and StatisticsSep. 2019 - Jul. 2023
Experience
-
 ByteDanceResearch InternDec. 2025 - present
ByteDanceResearch InternDec. 2025 - present -
 TeleAIResearch InternMar. 2025 - Dec. 2025
TeleAIResearch InternMar. 2025 - Dec. 2025
Honors & Awards
-
CETC The 14TH Research Institute Glarun Scholarship2024
-
Merit Student2024
-
Beijing Excellent Graduates2023
-
National Scholarship2022
-
National Scholarship2021
News
Selected Projects and Papers (view all )
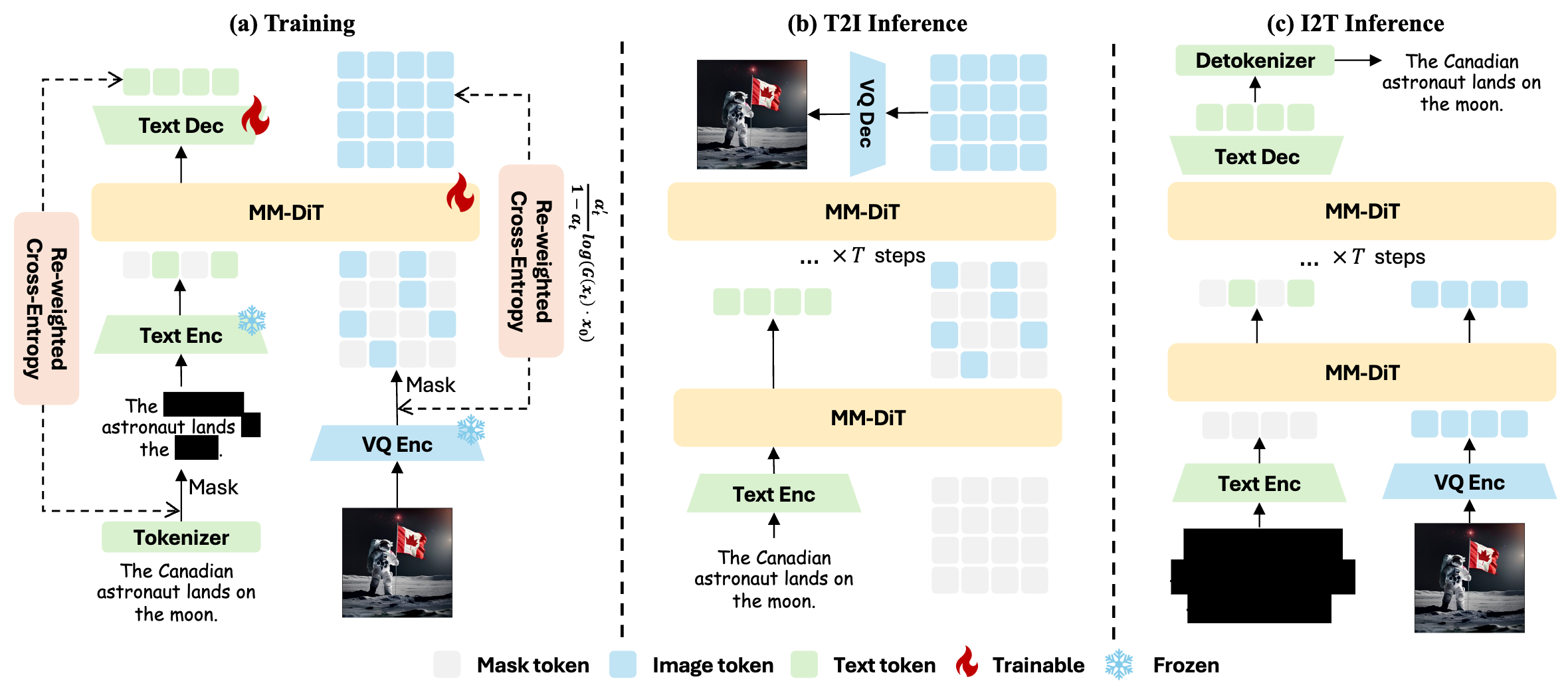
Beyond Text-to-Image: Liberating Generation with a Unified Discrete Diffusion Model
Qingyu Shi, Jinbin Bai, Zhuoran Zhao, Wenhao Chai, Kaidong Yu, Jianzong Wu, Shuangyong Song, Yunhai Tong, Xiangtai Li, Xuelong Li, Shuicheng YAN
Under review. 2025
We introduce Muddit, a unified discrete diffusion transformer that enables fast and parallel generation across both text and image modalities. Empirical results show that Muddit achieves competitive or superior performance compared to significantly larger autoregressive models in both quality and efficiency.
Beyond Text-to-Image: Liberating Generation with a Unified Discrete Diffusion Model
Qingyu Shi, Jinbin Bai, Zhuoran Zhao, Wenhao Chai, Kaidong Yu, Jianzong Wu, Shuangyong Song, Yunhai Tong, Xiangtai Li, Xuelong Li, Shuicheng YAN
Under review. 2025
We introduce Muddit, a unified discrete diffusion transformer that enables fast and parallel generation across both text and image modalities. Empirical results show that Muddit achieves competitive or superior performance compared to significantly larger autoregressive models in both quality and efficiency.

Decouple and Track: Benchmarking and Improving Video Diffusion Transformers For Motion Transfer
Qingyu Shi, Jianzong Wu, Jinbin Bai, Jiangning Zhang, Lu Qi, Yunhai Tong, Xiangtai Li
ICCV 2025 Poster
In this paper, we propose DeT, a method that adapts DiT models to improve motion transfer ability. Our approach introduces a simple yet effective temporal kernel to smooth DiT features along the temporal dimension, facilitating the decoupling of foreground motion from background appearance.
Decouple and Track: Benchmarking and Improving Video Diffusion Transformers For Motion Transfer
Qingyu Shi, Jianzong Wu, Jinbin Bai, Jiangning Zhang, Lu Qi, Yunhai Tong, Xiangtai Li
ICCV 2025 Poster
In this paper, we propose DeT, a method that adapts DiT models to improve motion transfer ability. Our approach introduces a simple yet effective temporal kernel to smooth DiT features along the temporal dimension, facilitating the decoupling of foreground motion from background appearance.

DreamRelation: Bridging Customization and Relation Generation
Qingyu Shi, Lu Qi, Jianzong Wu, Jinbin Bai, Jingbo Wang, Yunhai Tong, Xiangtai Li
CVPR 2025 Oral
We introduce DreamRelation, a framework that disentangles identity and relation learning using a carefully curated dataset. Our training data consists of relation-specific images, independent object images containing identity information, and text prompts to guide relation generation. Extensive results on our proposed benchmarks demonstrate the superiority of DreamRelation in generating precise relations while preserving object identities across a diverse set of objects and relationships.
DreamRelation: Bridging Customization and Relation Generation
Qingyu Shi, Lu Qi, Jianzong Wu, Jinbin Bai, Jingbo Wang, Yunhai Tong, Xiangtai Li
CVPR 2025 Oral
We introduce DreamRelation, a framework that disentangles identity and relation learning using a carefully curated dataset. Our training data consists of relation-specific images, independent object images containing identity information, and text prompts to guide relation generation. Extensive results on our proposed benchmarks demonstrate the superiority of DreamRelation in generating precise relations while preserving object identities across a diverse set of objects and relationships.